借助现代化的 ETL 工具,在云原生洞察平台上构建值得信赖的数据流程
多云、AI 驱动型数据集成
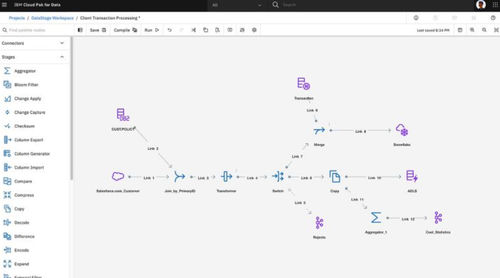
IBM® DataStage® 是一款行业领先的数据集成工具,可帮助您设计、开发和运行旨在移动和转换数据的作业。从核心功能看,DataStage 工具支持提取、转换和加载 (ETL) 以及提取、加载和转换 (ELT) 两类模式。该软件的基本版本可用于本地部署,但为了缩短数据集成时间和降低成本,可升级至 DataStage for IBM Cloud Pak for Data®,在混合或多云环境中体验其强大的自动集成功能。
DataStage 网络研讨会 - 10 月 5 日星期四
立即开始为您的 AI 实施构建可信的数据基础。加入我们,了解 IBM 数据整合工具 DataStage 和 IBM 的下一代数据存储 watsonx.data 的实际应用。
什么是 DataStage for IBM Cloud Pak for Data?
什么是 IBM Cloud Pak for Data?这是建立于 Red Hat® OpenShift® 容器编排平台上的云原生洞察平台,集成了 Data Fabric 体系结构内收集、整理和分析数据所需的诸多工具。它对分布式环境上的数据进行动态的智能化编排,从而为各类数据使用方创建即时可用的信息网络。IBM Cloud Pak for Data 既可部署在本地,也可作为 IBM Cloud® 上的一项服务运行,还可部署于任何供应商的云端环境上。
DataStage 可作为 IBM Cloud Pak for Data 软件许可证的附加组件,也可通过“IBM Cloud Pak for Data as a Service”作为一项服务运行。
优势
加速工作负载执行
借助工作负载均衡和并行引擎,可确保工作负载运行速度加快 30%¹。
阅读相关报告
降低数据移动成本
实现数据集成。只需一次设计,即可将运行时移动至数据存储位置。
阅读相关报告
实现数据集成现代化
在保留现有 DataStage 投资资产的同时,积极扩展各项功能。
查看此信息图
交付可信数据
在 IBM Cloud Pak for Data 上使用治理功能